
ChatGPT, Bard & Co.: an introduction to AI for competition and regulatory lawyers
Having its first commercial breakthrough with ChatGPT, in 2023 artificial intelligence (AI) has rung in the fourth industrial revolution. This article outlines the technicalities and economics underlying generative AI, and what they mean for competition in digital markets and for antitrust and regulatory lawyers working in this field.
I. What does ChatGPT stand for?
ChatGPT is an AI chatbot. The tool interprets human queries or requests that can be formulated in natural sentences (prompts) and answers or fulfills them comprehensively in a natural language in real-time. Technically, such software solutions are referred to as Large Language Model (LLM). Trained by vast amounts of text to identify connections between words, LLMs aim at predicting the likelihood of a word occurring in a text, given the context of the surrounding words.
ChatGPT stands for “Conversational Generative Pre-Training Transformer”.
- Chat relates to the electronic conversation via text that the service enables.
- Generative refers to the system’s ability to not copy-paste content it was trained with but to generate new text (or other content such as images or videos) on patterns it has learned from its training data. Instead of selecting a pre-defined response (such as an indexed answer to a query), the model produces coherent text in response to a prompt in a new, unique, order.
- Pre-Trained refers to the fact that the model has already been trained on a large amount of data before it was fine-tuned for the specific task of answering in a human chat-like form. This allows faster and more precise results than starting from scratch each time a user enters a prompt.
- Transformer relates to the architecture used to train the model. A transformer is a new type of “neural network” that is used for machine learning. It allows for the processing of longer text than previous methods, thereby overcoming memory limitations of older LLMs.
ChatGPT was released by OpenAI, a US-based firm founded in 2015, inter alia by Elon Musk. Since 2019, OpenAI has cooperated closely with Microsoft. Among other support, Microsoft allowed OpenAI to use its vast cloud infrastructure for free and assisted in training its LLM (GPT).[1]
II. What led to the hype around ChatGPT?
Reaching 1 million users in just 5 days and 100 million users in 2 months, ChatGPT is the fastest-growing consumer application to date.[2] But it was not only its functionality that took people’s imagination by storm and shook up the AI sector, but also the burgeoning “arms race” between tech giants for AI superiority.
With one of the largest AI labs on earth[3] Google had been pioneering the AI scene for years. It was Google engineers that in 2017 published a paper on the “transformer-based” AI model that led to OpenAI’s breakthroughs.[4] Google first demonstrated its own LLM, called LaMDA, in May 2021.[5] Reportedly due to “reputational risk” from providing incorrect information, Google decided against launching the service, and[6] for similar reasons, in November 2022, Meta stopped a test of its LLM chatbot called Galactica AI. Users had criticized the model as generating incorrect or biased content that “sounded right and authoritative.”[7]
Such concerns, however, did not stop OpenAI/Microsoft from launching ChatGPT on November 30, 2022. Users detected fewer biases because the AI had been specifically trained to handle sensitive questions. Yet, the issue of factual errors in the answers remained, because while (all) LLMs “are excellent at predicting the next word in a sentence [..] they have no knowledge of what the sentence actually means.”[8] Despite ChatGPT’s so-called “hallucinations,” the linguistic quality of the chatbot stunned even experts.[9]OpenAI/Microsoft quickly marketed the technology as a potential “killer” of the incumbent search engine Google, and not without success. Only a few days after the launch, Google declared a “code red”, an immediate threat to its advertising business.[10] Ever since, the world has paid close attention to the impending search ‘battle royale’ between Microsoft and Google. And it was entertaining indeed. Google invited the press to join a live event on February 8th in Paris to present its own AI-chatbot for search, called Bard. To use the moment, Microsoft and Chinese search giant Baidu decided to announce the integration of a chatbots (called Bing AI and Ernie Bot) into their search engines one day earlier, on February 7th.[11] Countering this marketing move, Google’s CEO then pre-announced Bard on February 6th. Yet, once experts noted that both Bard got the facts wrong in its very first public demo in Paris, Google’s stock value fell by US $ 100 billion in one day.[12] The fact that Microsoft’s Bing AI had also provided erroneous answers in its first public presentation went by largely unnoticed.[13]
III. How does ChatGPT fit into the broader AI industry?
In the wake of the AI hype, many new products and services powered by AI were launched. The emphasis is on “powered.” AI is neither a product nor a stand-alone service, but a system provided dynamically by some (‘providers’) and placed into various operations by others (‘deployers’).[14] AI is a broad term that refers to any wide range of technology from simple algorithms that sort data, to more advanced systems that can mimic human-like thought processes. ChatGPT’s advances are linked to a new generation of AI systems, so-called large foundation models, of which LLMs are a sub-category. A foundation model is an advanced system of “deep” machine learning that is trained on broad data that can subsequently be fine-tuned to a wide range of downstream tasks. While such models had been around for a while, over the last few years improvements in computer hardware allowed the building of ever larger models, resulting in the current capabilities.
IV. What does Machine Learning & AI involve?
Put simply, AI development involves five stages (the ‘AI stack’):
1. Data creation & collection: Any machine learning requires the creation and collection of some raw data. Since almost all data are created by people and/or about people, data can be gathered through different tools, stretching from Internet crawl to the scanning of proprietary data bases. Once data are collected, they are stored and secured in data centers. In the early days, companies stored their data in their own brick-and-mortar data centers. But data storage is increasingly shifting to the cloud, where companies access their data through the internet from cloud service providers.
2. Data curation: Generated data needs to be prepared and curated into suitable datasets. This involves the effort to convert, clean, enhance, format, and label (created and stored) raw data to make it consistent and usable.
3. Training of foundation models: The celebrated centerpiece in the recent rise of AI is the training of a foundation model with the curated datasets. As with all machine learning, such training involves the configuration of an algorithm to make any relevant predictions from the data.
4. Adaptation (fine-tuning): While particularly powerful, foundation models are intermediary assets; they are generally not used directly but require an adaptation for specific downstream tasks. Such adaption centers on the so-called fine-tuning that adjusts foundation models to perform specific tasks of interest. Beyond that, adaptation may also involve alleviating deficiencies of stand-alone foundations models, for instance, to make them legally compliant.
5. Deployment: Once a fine-tuned AI model has been developed, it needs to be turned into a commercially viable product or service that is deployed by people. This task is typically carried out by software programmers or app developers that bring the fine-tuned models to life. Often the value chain does not end but actually starts here: entrepreneurs first identify a commercially promising business case for a product or service.
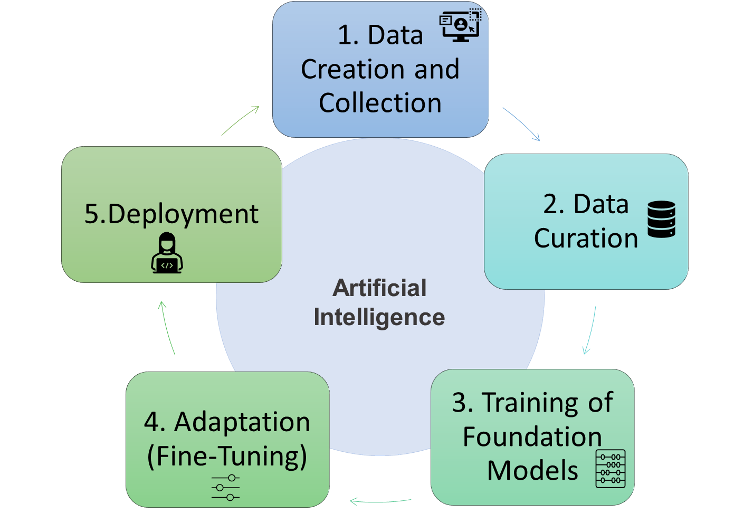
Illustration 1: The Artificial Intelligence Value Chain
V. What are the relevant markets and business models around AI?
Some large tech companies operate the entire AI stack in-house. Such companies may use their “closed AI systems” to improve their own products and services or to sell their final AI-powered products and services on the markets. However, AI development is subject to strong economies of scale and scope. In summary, bigger models produce better results. Most AI companies therefore focus on particular steps of the value chain and outsource others. With a view to bringing down costs and increasing adaptation and development by others, there are several open-source foundation models, that anyone may use. However, some AI tools and services are only provided for a price. As a result, while the industry is still at an early stage, with a view to categorizing the relevant players, a broad distinction can be drawn between the following four types of service providers:
1. Computer service providers provide all the hardware (chips, servers, data centers) and software components for the coordinated storage of data, the training of the algorithms and the subsequent inference (operation) of the AI models once they are deployed. They can be further sub-divided into sellers of computer hardware and providers of cloud platform services.
2. Data service providers offer services regarding the creation, collection or preparation of data required to train upstream and downstream AI models. This may also involve any service relating to the measurement and evaluation of data.
3. Foundation modelling service providers combine the data to develop and train large algorithms for a broad, general user case (e.g. LLMs) They can be sub-divided in providers of closed-source foundation models, which are provided via an API for a licensing fee (e.g. GPT-3) and open-source foundation models that are released for open use (e.g. CLIP). There are also companies that specialize in sharing and hosting open-source foundation models. They can be referred to as model host providers.
4. Application developers develop end-user facing AI applications. Those can be a software, device or application that consumers or business users may use and pay for. AI developers can be further sub-divided into providers of “end-to-end apps” that are entirely based on proprietary AI models, and developers that rely on AI models developed by third parties (made available either via a proprietary APIs or as open-source checkpoints by a model host). All of them fine-tune AI to specific use cases, e.g. by enriching them with specific datasets or additional training of models.
VI. AI as a platform
There are strong interdependencies and overlaps between these AI layers and players. Businesses in the AI sector cooperate with the common goal of enhancing its abilities and expanding its deployment. Some therefore consider AI as a new form of digital platform akin to operating systems. Instead of everyone doing everything, a few companies take a very broad set of data and train a large foundation model that learns to perform a general set of functions. This model is then made available to many other developers that may fine-tune it to more specific applications and uses. Thus, while few companies (like OpenAI) will create foundation models and give access to developers, many developers will build applications on top and tailor them to specific industries or markets. The downstream developers thereby benefit from the large investments into the upstream model, while adding value by means of their own applications.[15] This turns foundation models into platforms, akin to B2B app stores; a “product” that AI developers use as a basis for their adaptations in return for licensing fees or contributions in term of access to users and data.
Such platform model may be the starting point for many AI applications. However, commercial operators of foundation models will also seek to capture value from the downstream levels by vertically integrating. Like OpenAI, they will likely license the upstream models and sell their own applications. This would be equivalent to Apple and Google operating app stores on their iOS and Android devices while also selling apps on them.
The AI value chain can be illustrated as follows:
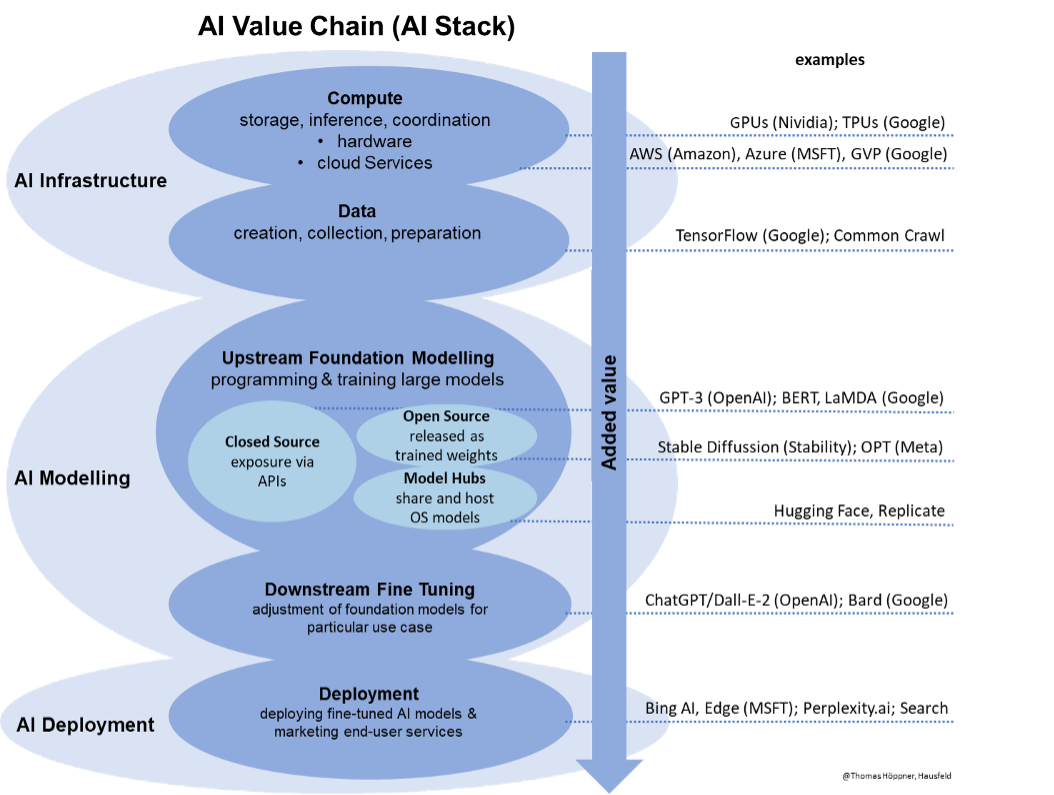
Illustration 2: The AI Stack
VII. What are the barriers to entry and who will likely succeed in the AI arms race?
It is difficult to foresee which companies will ultimately dominate which elements of the AI stack. However, the current market conditions and economics of AI suggest that apart from the level of AI deployment, the relevant markets will be highly concentrated and largely in the hands of the big tech incumbents, namely Amazon, Apple, Google, Microsoft and Meta:
1. Concentration at the AI computer level: Nearly everything that relates to AI depends on computational performance and therefore passes through cloud services at some point. Computing power is the lifeblood of AI,[16] turning cloud service providers into unavoidable trading partners for most businesses. Reportedly, training GPT-3 “required far more computing power than Microsoft’s systems had ever handled before.”[17] Microsoft had to strike a deal with the leading chipmaker Nvidia to develop the fifth largest “supercomputer” on earth to handle the workload of GPT-3.[18] Insiders estimate that “on average,” AI application developers “spend around 20-40% of revenue on inference and per-customer fine-tuning. This is typically paid either directly to cloud providers or to third-party model providers – who, in turn, spend about half their revenue on cloud infrastructure.”[19] A very large part (some estimate 80-90% in early funding rounds[20]) of the billions of dollars in venture capital that currently flows into startups training their own AI models, is spent at the “big three” cloud providers: Amazon, Microsoft and Google. These “infrastructures vendors are likely the biggest winners”[21] in the AI race, capturing the majority of dollars flowing through the AI stack. Globally Amazon “is the unquestionable leader in the cloud computing infrastructure market.”[22] In Europe 2020, Amazon (AWS) and Microsoft (Azure) both had “market shares of between 35% and 40%. [Google Cloud Platform] GCP and Oracle follow [..] with a market share of between 5% and 10%. The ‘others’ category contains operators that only have a market share of a few percent”[23] The barriers to entry are very high, but the potential profit margin huge. Thus, revenues from cloud services provide the strongest commercial incentive for the mentioned giants to push the AI wave.
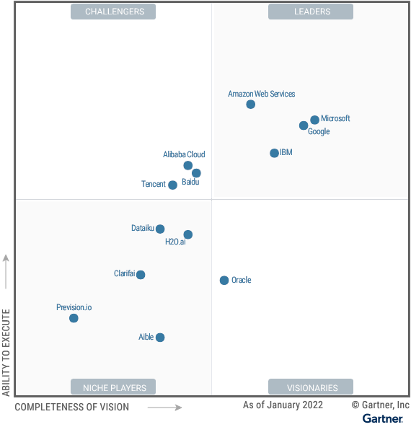
Illustration 3: Gartner 2022 Magic Quadrant for Cloud AI Developer Services
2. Concentration at the AI data creation level: Once the computational restraints are resolved, data will likely be one of the most important factors for the success of any AI endeavor. ChatGPT was criticized for generating outdated answers, partly due to the fact that the model was trained only until 2021. The success of future models will depend on real-time access to relevant data, with business and personal data being the most relevant source.[24] Accordingly, those who control the internet-connected devices and services that collect and amass most data will also be in the lead for any AI applications. This gives big tech “gatekeepers” a competitive head-start. Their control over core digital platform services (such as operating systems, browsers, cloud services or voice assistants) will provide them with better access to valuable datasets than any AI start-up will ever have. Google and Microsoft, in particular, are the only western operators of general search engines left that constantly crawl and index the entire web as the richest data source for any generative AI.[25]
3. Concentration at the AI modeling level: The foundation model is “only one component (though an increasingly important component) of an AI system.”[26] However, “building a very good model is still extremely hard. There are just a few people in the world who are able to do that.”[27] And those few are drawn to big tech. Of the (only) eleven private large foundation models that have been set up since the breakthrough of GPT-3 in year 2020, eight are operated by digital gatekeepers (five by Google/DeepMind, one by Meta, Microsoft and Baidu respectively). Since 2017, 86% of the published foundation models have been developed by private commercial organizations--only 13% in the academic sector.[28] 73 % of foundation models have been developed in the US, 15% in China. The few models from Europe tend to be smaller, less extensively trained, and mainly adjust the GPT architecture to national markets. None of the best-known models representing breakthroughs came from Europe.[29]
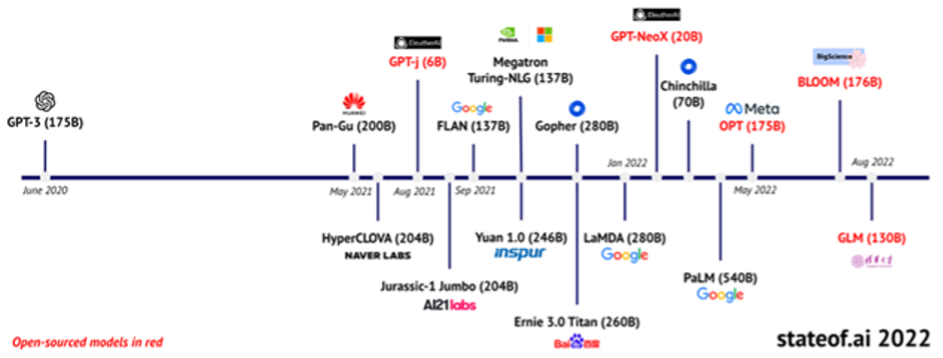
Illustration 4: Global LLMs (source: Benaich/Hogarth, State of AI Report 2022[30])
4. Concentration at the AI development level: AI products can come in a number of different forms: desktop apps, mobile apps, plugins, and browser extensions to name a few. The deployment layer of the AI stack is destined to see the most diverse range of companies. However, considering the central resources required for a successful deployment of AI models, digital incumbents are also at a privileged position at this layer of the AI stack. They have the infrastructure, engineers, users, and data to identify, develop and distribute promising applications at scale. It is much easier to integrate AI in products or services that users already use. Generative AI, for instance, can be embedded into nearly any user interface, simply with a text box. Accordingly, it is likely that by integrating AI into their huge product lines, the current digital gatekeepers likely will seek to leverage their positions also into the most lucrative downstream markets for AI applications. Such gatekeepers also have the most powerful tools to suppress the diffusion of any rival AI offerings.[31]
AI is subject to strong economies of scale and scope. More extensive infrastructure allows better foundation models, better foundation models invite more developers that build better applications, better applications lead to larger deployment which generates revenues that brings capital to invest in even more infrastructure to build even larger foundation models, etc. That self-reinforcing growth cycle appears very real in AI. And it means that the big get bigger and the small get smaller as they lack the scale to generate positive network effects or cost-related economies of scope. As the Centre for Research on Foundation Models (CRFM) rightly concluded: “The fundamental centralizing nature of foundation models means that the barrier to entry for developing them will continue to rise, so that even startups, despite their agility, will find it difficult to compete, a trend that is reflected in the development of search engines.”[32]
VIII. What are the likely frontiers of antitrust and regulation around AI?
Within just a few weeks, ChatGPT, Bing AI and Bard impressively demonstrated that AI is a blessing for some and a curse for others. Despite, promising to solve many problems of human kind, the systems pose significant risks for society, from mass plagiarism to spreading disinformation that may lead to a further loss of trust in any media or the state and further polarization and radicalization. It is not reassuring in this context, that the essential AI resources are concentrated in the hands of big commercial tech companies whose legal and ethical standards have been questioned in the past.
Regarding competition, the characteristics of the AI stack have all ingredients for winner-takes-all battles with significant collateral damage affecting third party businesses: (i) Vertical integration in closely interrelated markets, with (ii) upstream dominance and downstream value generation, (iii) unequal access to proprietary resources, (iv) issues of interoperability, (v) data portability, (vii) non-transparency, (vii) IP licensing, and (viii) platform usage fees and conditions vis-á-vis dependent business users, etc. The incentives and abilities of incumbents to exploit, leverage and further entrench their market positions are evident. And this is not even considering the particularities of specific AI applications such as the explo2itation of creative industries for generative AI (that uses their content to create competing services) or the tacit collusion within harmonized AI models deployed by competing companies.
With the proposed ‘AI Act’ for harmonizing the conditions to offer AI services in the EU[33], the Digital Services Act (DSA) as well as the Digital Markets Act (DMA), Europe is arguably better prepared to meet this challenge than most other jurisdictions from an antitrust and broader regulatory perspective. While the DMA in particular (somewhat surprisingly) does not mention AI or machine learning once, it (fortunately) lists “online intermediation services,” “virtual assistants,” “search engines” and, most importantly, “cloud computing services” as “core platform services” (Art. 2 para. 2). Designated gatekeepers will have to comply with Articles 5 to 7 DMA as regards those services. This means, for instance, that these companies may not use any data provided by business users in the context of a cloud computing service to adjust their own AI offerings.[34] However, as the notion of “AI as a platform” had not been anticipated, the DMA (and possibly also the DSA) would need to be updated to address the specific competition issues around AI. It will pay that such legislation is flexible and provides for regular updates.
In the US, neither the proposed American Innovation and Choice in Online Markets Act nor the proposed Open App Markets Act presently contain specific provisions on AI. Given that it is still debated whether digital markets require any adjustment of US antitrust laws at all, US enforcers are in a (even) weaker position to address any competition concerns arising from the use of AI resources to gain unwarranted advantages.
IX. A look ahead
Due to high barriers to entry at the (i) computing, (ii) data creation, and (iii) foundation modelling layers of the AI stack, the rise of AI is prone to make big tech companies even more powerful. Their vertical integration across the AI value chain creates conflicts of interest that may quickly lead to anti-competitive leveraging conduct. Since the entire system is highly opaque, such conduct will be difficult to detect and challenge, even for well-equipped public enforcement authorities. In similar previous scenarios, antitrust intervention kicked in “too late” or was “too weak” to prevent irreparable harm.[35] It is to be hoped that this time around competition law will be better prepared to deal with the many challenges ahead.*
*Thomas Höppner is a partner in Berlin. Luke Streatfeild is a partner in London. Hausfeld in representing various businesses in relation to Big Tech.
Footnotes
[1] https://blogs.microsoft.com/blog/2023/01/23/microsoftandopenaiextendpartnership/
[2] https://www.republicworld.com/technology-news/apps/chatgpt-becomes-fastest-growing-app-with-100-million-active-users-in-just-2-months-articleshow.html
[3] See https://www.theinforma,tion.com/articles/facebook-google-in-deep-learning-arms-race?rc=ct4xax
[4] Vasmani et al., Attention is All You Need, 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
[5] https://blog.google/technology/ai/lamda/
[6] https://www.cnbc.com/2022/12/13/google-execs-warn-of-reputational-risk-with-chatgbt-like-tool.html
[7] https://www.siliconrepublic.com/machines/galactica-meta-ai-large-language-model
[8] https://www-technologyreview-com.cdn.ampproject.org/c/s/www.technologyreview.com/2023/02/14/1068498/why-you-shouldnt-trust-ai-search-engines/amp/
[9] For more details on the technology see https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
[10] https://www.nytimes.com/2022/12/21/technology/ai-chatgpt-google-search.html
[11] https://fortune.com/2023/02/07/microsofts-bing-google-bard-baidu-ernie-chatgpt-chatbot-battle-for-search-begins/
[12] https://www.theverge.com/2023/2/8/23590864/google-ai-chatbot-bard-mistake-error-exoplanet-demo
[13] https://fortune.com/2023/02/15/microsoft-bing-ai-errors-demo-google-bard-chatgpt/
[14] Edwards, Regulating AI in Europe: four problems and four solutions, March 2022, p. 6 f. https://www.adalovelaceinstitute.org/wp-content/uploads/2022/03/Expert-opinion-Lilian-Edwards-Regulating-AI-in-Europe.pdf
[15] See https://news.microsoft.com/source/features/ai/openai-azure-supercomputer/ quoting OpenAI CEO Sam Altman: “One advantage to the next generation of large AI models is that they only need to be trained once with massive amounts of data and supercomputing resources. A company can take a ‘pre-trained’ model and simply fine tune for different tasks with much smaller datasets and resources.”
[16] https://a16z.com/2023/01/19/who-owns-the-generative-ai-platform/
[17] https://www.theinformation.com/articles/microsoft-openai-inside-techs-hottest-romance?rc=ct4xax
[18] https://www.theinformation.com/articles/microsoft-openai-inside-techs-hottest-romance?rc=ct4xax
[19] https://synthedia.substack.com/p/the-most-interesting-analysis-of?tm_source=substack&utm_campaign=post_embed&utm_medium=web
[20] https://a16z.com/2023/01/19/who-owns-the-generative-ai-platform/
[21] https://a16z.com/2023/01/19/who-owns-the-generative-ai-platform/
[22] Majority Staff Report, Committee on the Judiciary, U.S. House of Representatives 37 (2020), at 113
[23] Netherlands Authority for Consumers and Markets, Case no. ACM/21/050317, Market Study Cloud Services, 2022, p. 34 https://www.acm.nl/system/files/documents/public-market-study-cloud-services.pdf
[24] CRFM, The Opportunities and Risks of Foundation Models, 2021, p. 8, https://arxiv.org/abs/2108.07258
[25] Content crawled from the web was by far the main dataset to train GPT, see https://dzlab.github.io/ml/2020/07/25/gpt3-overview/
[26] CRFM, The Opportunities and Risks of Foundation Models, 2021, p. 8, https://arxiv.org/abs/2108.07258
[27] Clement Delangue, CEO of Hugging Face in TheInformation, “Don’t Sleep on Google in AI Battle with OpenAI and Microsoft”, 2023 https://www.theinformation.com/articles/dont-sleep-on-google-in-ai-battle-with-openai-and-microsoft-says-a-key-former-engineer?rc=ct4xax
[28] LEAM:AI, Large AI Models for Germany -Feasibility Study 2023, p. 56. https://leam.ai/feasibility-study-leam-2023/
[29] LEAM:AI, Large AI Models for Germany -Feasibility Study 2023, p. 56. https://leam.ai/feasibility-study-leam-2023/
[30] https://www.stateof.ai/
[31] See Höppner, Creative Destruction in Digital Ecosystems Revisited, in this Bulletin.
[32] CRFM, The Opportunities and Risks of Foundation Models, 2021, p. 11, https://arxiv.org/abs/2108.07258
[33] Regulation laying down harmonized rules on artificial intelligence and amending certain union legislative acts, SEC(2021) 167 final} - {SWD(2021) 84 final https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A52021PC0206
[34] See recital (48) DMA.
[35] The case bears some resemblance with Google conquering the entire ad tech stack, see DoJ et all, Case 1:23-cv-00108, Google Ad Tech Complaint for Monopolizing Digital Advertising Technologies, https://www.justice.gov/opa/press-release/file/1563746/download




